15 KiB
Kohya's GUI
This repository provides a Windows-focused Gradio GUI for Kohya's Stable Diffusion trainers. The GUI allows you to set the training parameters and generate and run the required CLI commands to train the model.
If you run on Linux and would like to use the GUI, there is now a port of it as a docker container. You can find the project here.
Table of Contents
- Tutorials
- Required Dependencies
- Installation
- Upgrading
- Launching the GUI
- Dreambooth
- Finetune
- Train Network
- LoRA
- Troubleshooting
- Change History
Tutorials
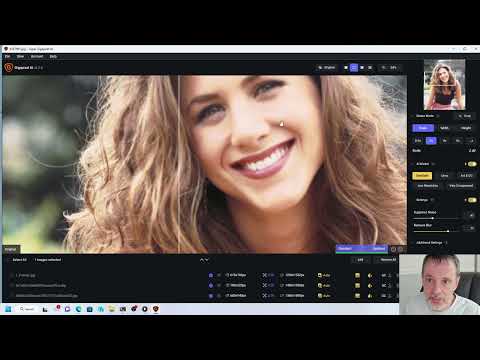
How to Create a LoRA Part 1: Dataset Preparation:
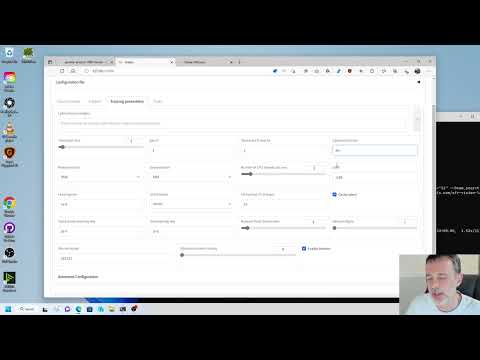
How to Create a LoRA Part 2: Training the Model:
Required Dependencies
- Install Python 3.10
- make sure to tick the box to add Python to the 'PATH' environment variable
- Install Git
- Install Visual Studio 2015, 2017, 2019, and 2022 redistributable
Installation
Ubuntu
In the terminal, run
git clone https://github.com/bmaltais/kohya_ss.git
cd kohya_ss
bash ubuntu_setup.sh
then configure accelerate with the same answers as in the Windows instructions when prompted.
Windows
Give unrestricted script access to powershell so venv can work:
- Run PowerShell as an administrator
- Run
Set-ExecutionPolicy Unrestrictedand answer 'A' - Close PowerShell
Open a regular user Powershell terminal and run the following commands:
git clone https://github.com/bmaltais/kohya_ss.git
cd kohya_ss
python -m venv venv
.\venv\Scripts\activate
pip install torch==1.12.1+cu116 torchvision==0.13.1+cu116 --extra-index-url https://download.pytorch.org/whl/cu116
pip install --use-pep517 --upgrade -r requirements.txt
pip install -U -I --no-deps https://github.com/C43H66N12O12S2/stable-diffusion-webui/releases/download/f/xformers-0.0.14.dev0-cp310-cp310-win_amd64.whl
cp .\bitsandbytes_windows\*.dll .\venv\Lib\site-packages\bitsandbytes\
cp .\bitsandbytes_windows\cextension.py .\venv\Lib\site-packages\bitsandbytes\cextension.py
cp .\bitsandbytes_windows\main.py .\venv\Lib\site-packages\bitsandbytes\cuda_setup\main.py
accelerate config
Optional: CUDNN 8.6
This step is optional but can improve the learning speed for NVIDIA 30X0/40X0 owners. It allows for larger training batch size and faster training speed.
Due to the file size, I can't host the DLLs needed for CUDNN 8.6 on Github. I strongly advise you download them for a speed boost in sample generation (almost 50% on 4090 GPU) you can download them here.
To install, simply unzip the directory and place the cudnn_windows folder in the root of the this repo.
Run the following commands to install:
.\venv\Scripts\activate
python .\tools\cudann_1.8_install.py
Upgrading
When a new release comes out, you can upgrade your repo with the following commands in the root directory:
git pull
.\venv\Scripts\activate
pip install --use-pep517 --upgrade -r requirements.txt
Once the commands have completed successfully you should be ready to use the new version.
Launching the GUI
To run the GUI, simply use this command:
.\gui.ps1
or you can also do:
.\venv\Scripts\activate
python.exe .\kohya_gui.py
Dreambooth
You can find the dreambooth solution specific here: Dreambooth README
Finetune
You can find the finetune solution specific here: Finetune README
Train Network
You can find the train network solution specific here: Train network README
LoRA
Training a LoRA currently uses the train_network.py code. You can create a LoRA network by using the all-in-one gui.cmd or by running the dedicated LoRA training GUI with:
.\venv\Scripts\activate
python lora_gui.py
Once you have created the LoRA network, you can generate images via auto1111 by installing this extension.
Troubleshooting
Page File Limit
- X error relating to
page file: Increase the page file size limit in Windows.
No module called tkinter
- Re-install Python 3.10 on your system.
FileNotFoundError
This is usually related to an installation issue. Make sure you do not have any python modules installed locally that could conflict with the ones installed in the venv:
- Open a new powershell terminal and make sure no venv is active.
- Run the following commands:
pip freeze > uninstall.txt
pip uninstall -r uninstall.txt
This will store your a backup file with your current locally installed pip packages and then uninstall them. Then, redo the installation instructions within the kohya_ss venv.
Change History
-
2023/03/09 (v21.2.0):
-
Add option to print LoRA trainer command without executing it
-
Add support for samples during trainin via a new
Sample images configaccordion in theTraining parameterstab. -
Added new
Additional parametersunder theAdvanced Configurationsection of theTraining parameterstab to allow for the specifications of parameters not handles by the GUI. -
Added support for sample as a new Accordion under the
Training parameterstab. More info about the prompt options can be found here: https://github.com/kohya-ss/sd-scripts/issues/256#issuecomment-1455005709 -
There may be problems due to major changes. If you cannot revert back to the previous version when problems occur, please do not update for a while.
-
Minimum metadata (module name, dim, alpha and network_args) is recorded even with
--no_metadata, issue https://github.com/kohya-ss/sd-scripts/issues/254 -
train_network.pysupports LoRA for Conv2d-3x3 (extended to conv2d with a kernel size not 1x1).- Same as a current version of LoCon. Thank you very much KohakuBlueleaf for your help!
- LoCon will be enhanced in the future. Compatibility for future versions is not guaranteed.
- Specify
--network_argsoption like:--network_args "conv_dim=4" "conv_alpha=1" - Additional Networks extension version 0.5.0 or later is required to use 'LoRA for Conv2d-3x3' in Stable Diffusion web UI.
- Stable Diffusion web UI built-in LoRA does not support 'LoRA for Conv2d-3x3' now. Consider carefully whether or not to use it.
-
Merging/extracting scripts also support LoRA for Conv2d-3x3.
-
Free CUDA memory after sample generation to reduce VRAM usage, issue https://github.com/kohya-ss/sd-scripts/issues/260
-
Empty caption doesn't cause error now, issue https://github.com/kohya-ss/sd-scripts/issues/258
-
Fix sample generation is crashing in Textual Inversion training when using templates, or if height/width is not divisible by 8.
-
Update documents (Japanese only).
-
Dependencies are updated, Please upgrade the repo.
-
Add detail dataset config feature by extra config file. Thanks to fur0ut0 for this great contribution!
- Documentation is here (only in Japanese currently.)
- Specify
.tomlfile with--dataset_configoption. - The options supported under the previous release can be used as is instead of the
.tomlconfig file. - There might be bugs due to the large scale of update, please report any problems if you find at https://github.com/kohya-ss/sd-scripts/issues.
-
Add feature to generate sample images in the middle of training for each training scripts.
--sample_every_n_stepsand--sample_every_n_epochsoptions: frequency to generate.--sample_promptsoption: the file contains prompts (each line generates one image.)- The prompt is subset of
gen_img_diffusers.py. The prompt optionsw, h, d, l, s, nare supported. --sample_sampleroption: sampler (scheduler) for generating, such as ddim or k_euler. See help for useable samplers.
-
Add
--tokenizer_cache_dirto each training and generation scripts to cache Tokenizer locally from Diffusers.- Scripts will support offline training/generation after caching.
-
Support letents upscaling for highres. fix, and VAE batch size in
gen_img_diffusers.py(no documentation yet.) -
Sample image generation: A prompt file might look like this, for example
# prompt 1 masterpiece, best quality, 1girl, in white shirts, upper body, looking at viewer, simple background --n low quality, worst quality, bad anatomy,bad composition, poor, low effort --w 768 --h 768 --d 1 --l 7.5 --s 28 # prompt 2 masterpiece, best quality, 1boy, in business suit, standing at street, looking back --n low quality, worst quality, bad anatomy,bad composition, poor, low effort --w 576 --h 832 --d 2 --l 5.5 --s 40Lines beginning with
#are comments. You can specify options for the generated image with options like--nafter the prompt. The following can be used.--nNegative prompt up to the next option.--wSpecifies the width of the generated image.--hSpecifies the height of the generated image.--dSpecifies the seed of the generated image.--lSpecifies the CFG scale of the generated image.--sSpecifies the number of steps in the generation.
The prompt weighting such as
( )and[ ]are not working.
Please read Releases for recent updates.
-
2023/03/05 (v21.1.5):
- Add replace underscore with space option to WD14 captioning. Thanks @sALTaccount!
- Improve how custom preset is set and handles.
- Add support for
--listenargument. This allow gradio to listen for connections from other devices on the network (or internet). For example:gui.ps1 --listen "0.0.0.0"will allow anyone to connect to the gradio webui. - Updated
Resize LoRAtab to support LoCon resizing. Added new resize
-
2023/03/05 (v21.1.4):
- Removing legacy and confusing use 8bit adam chackbox. It is now configured using the Optimiser drop down list. It will be set properly based on legacy config files.
-
2023/03/04 (v21.1.3):
- Fix progress bar being displayed when not required.
- Add support for linux, thank you @devNegative-asm
-
2023/03/03 (v21.1.2):
- Fix issue https://github.com/bmaltais/kohya_ss/issues/277
- Fix issue https://github.com/bmaltais/kohya_ss/issues/278 introduce by LoCon project switching to pip module. Make sure to run upgrade.ps1 to install the latest pip requirements for LoCon support.
-
2023/03/02 (v21.1.1):
- Emergency fix for https://github.com/bmaltais/kohya_ss/issues/261
-
2023/03/02 (v21.1.0):
- Add LoCon support (https://github.com/KohakuBlueleaf/LoCon.git) to the Dreambooth LoRA tab. This will allow to create a new type of LoRA that include conv layers as part of the LoRA... hence the name LoCon. LoCon will work with the native Auto1111 implementation of LoRA. If you want to use it with the Kohya_ss additionalNetwork you will need to install this other extension... until Kohya_ss support it natively: https://github.com/KohakuBlueleaf/a1111-sd-webui-locon
-
2023/03/01 (v21.0.1):
- Add warning to tensorboard start if the log information is missing
- Fix issue with 8bitadam on older config file load
-
2023/02/27 (v21.0.0):
- Add tensorboard start and stop support to the GUI
-
2023/02/26 (v20.8.2):
- Fix issue https://github.com/bmaltais/kohya_ss/issues/231
- Change default for seed to random
- Add support for --share argument to
kohya_gui.pyandgui.ps1 - Implement 8bit adam login to help with the legacy
Use 8bit adamcheckbox that is now superceided by theOptimizerdropdown selection. This field will be eventually removed. Kept for now for backward compatibility.
-
2023/02/23 (v20.8.1):
- Fix instability training issue in
train_network.py.fp16training is probably not affected by this issue.- Training with
floatfor SD2.x models will work now. Also training with bf16 might be improved. - This issue seems to have occurred in PR#190.
- Add some metadata to LoRA model. Thanks to space-nuko!
- Raise an error if optimizer options conflict (e.g.
--optimizer_typeand--use_8bit_adam.) - Support ControlNet in
gen_img_diffusers.py(no documentation yet.)
- Fix instability training issue in
-
2023/02/22 (v20.8.0):
- Add gui support for optimizers:
AdamW, AdamW8bit, Lion, SGDNesterov, SGDNesterov8bit, DAdaptation, AdaFactor - Add gui support for
--noise_offset - Refactor optmizer options. Thanks to mgz-dev!
- Add
--optimizer_typeoption for each training script. Please see help. Japanese documentation is here. --use_8bit_adamand--use_lion_optimizeroptions also work and will override the options above for backward compatibility.
- Add
- Add SGDNesterov and its 8bit.
- Add D-Adaptation optimizer. Thanks to BootsofLagrangian and all!
- Please install D-Adaptation optimizer with
pip install dadaptation(it is not in requirements.txt currently.) - Please see https://github.com/kohya-ss/sd-scripts/issues/181 for details.
- Please install D-Adaptation optimizer with
- Add AdaFactor optimizer. Thanks to Toshiaki!
- Extra lr scheduler settings (num_cycles etc.) are working in training scripts other than
train_network.py. - Add
--max_grad_normoption for each training script for gradient clipping.0.0disables clipping. - Symbolic link can be loaded in each training script. Thanks to TkskKurumi!
- Add gui support for optimizers: